노는게 제일 좋습니다.
tensorflow 4 : linear regression 본문
https://www.inflearn.com/course-status-2/
이곳을 보고 공부했다. 쉽게 설명해주셔서 초심자도 이렇게 공부노트를 적고있다.
그려놓은 그림과 코드 모두 이 주소를 참고해서 .. 뇌속에 복사했다 손으로 붙여넣기 했다.
linear regression
일차함수로 학습시키는 리그레션(regression).

트레이닝 셋을 평면좌표에 나타냈다. 검은 점이 트레이닝 셋의 실제 데이터들이다.
Linear Hypothesis(이하 선형 가설)란, 가장 적절한 선을 찾는 것이다.
이 선들은 H(x) = Wx + b 와 같이 나타낼 수 있다.
가장 적절한 선이란, 실제 데이터들의 점을 가장 가까이 지나는 선이라고 할 수 있다.

즉, 다음과 같이 하나의 선형가설과 트레이닝셋 데이터들의 거리를 비교한다.
각각의 데이터와의 거리는 H(x)-y와 같이 표현할 수 있다.
또는, ( H(x)-y )^2 와 같이 표현할 수 있다. 이 경우 음수가 없고, 거리가 먼 경우 더 큰 페널티를 주는 효과가 있다.
이 때, 거리를 측정한다고 했는데. 그렇다면 어떤 선형가설이 좋은것인가?
H(x)-y의 값은 작으면 작을 수록 좋다. 따라서, H(x)-y이 최소가 되게 하는 선형가설이 가장 좋다.
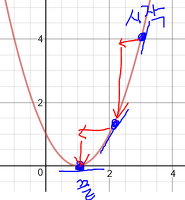
그러니 우리는, H(x)-y를 최소로 만드는 W,b의 값을 찾으면된다.
이런식으로 거리를 계산해서 딱좋은 선을 찾도록 도와주는 함수가 cost function(loss function)이다.
cost함수를 사용하면, 현재 세운 선형공식과 실제 데이터사이의 거리가 얼마나 큰지 알 수 있다.


그걸 함수로 나타내면 이렇게 된다.

사실 별거 없고. 그냥 H(x)-y값들을 싹다 더해서 평균낸거다.
지금까지 한 이야기를 코드로 짜면 이렇게 된다.
import tensorflow as tf
x_data = [1,2,3]
y_data = [1,2,3]
W = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
b = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
hypothesis = W*X + b
cost = tf.reduce_mean(tf.square(hypothesis-Y))
a=tf.Variable(0.1)
optimizer = tf.train.GradientDescentOptimizer(a)
train = optimizer.minimize(cost)
init=tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
for step in range(2001):
sess.run(train, feed_dict={X:x_data, Y:y_data})
if step %20 == 0:
print (step, sess.run(cost, feed_dict={X:x_data, Y:y_data}), sess.run(W), sess.run(b))
'Python > 통계 및 데이터관련' 카테고리의 다른 글
| tensorflow 6 : multi-variable Linear Regression (2) | 2017.01.15 |
|---|---|
| tensorflow 5 : Gradient Descent Algorithm (0) | 2017.01.14 |
| tensorflow 3 : 헬로월드 (0) | 2017.01.05 |
| tensorflow 2 : 텐서플로우 깔기 (0) | 2017.01.05 |
| tensorflow 1 : 머신러닝이란 (0) | 2017.01.05 |